
Unearthing problems by reducing work-in-progress
BUILDING BRIDGES - This month, we hear how addressing work-in-progress led a startup specialized in AI to productivity gains on their machine learning projects.
Words: Pierre-Henri Cumenge, Co-Founder, Sicara - Paris, France
At Sicara we have been focusing more and more on computer vision projects [computer vision is the science enabling computers to see, recognize and process images like the human eye would].
The best-performing algorithms in this field are called neural networks, since they loosely imitate the workings of the human brain (whereby each input goes through different, interconnected layers of “neurons”). To function, neural networks need to be “trained” - ingest thousands of images with a known content to adjust their internal parameters and be able to recognize the content of a new image. For instance, if I want to build an algorithm that detects cars in images, I will first train it to use images that I already know have cars in it. The algorithm will then be able to determine whether a new image contains a car.
In computer vision projects, testing algorithm improvements is a key task for our data scientists, one that seems inherently unpredictable: we don’t know in advance the results we will obtain nor the time required to train a new algorithm.
When we first began to work on computer vision and to discuss projects with team members, there seemed to be many problems. However, these typically didn’t relate to delays or unmet quality standards. Looking into our team’s approach, we spent time analyzing the process for each new experiment. This entails:
- Coding the algorithm and launching its training;
- While the training takes place, keeping the functionality card in “doing” and start working on a new task. This waiting phase can last several days;
- Going back to the experiment once the training is complete to extract the results.
It became clear that having several in-progress tasks for each team member was making it hard to estimate the time required for each task and hence to measure productivity issues. For example, we discovered afterwards some hidden rework: the team had been working on trainings that had failed and needed to be relaunched.
We looked in more detail at what a data scientist does when working on a new experiment, and found the process could be broken down in five steps. To illustrate this, let’s take a concrete example from one of our projects. The team had been training a neural network called MaskRCNN on photographs of flat surfaces taken from an angle, in order to automatically recognize objects in these images for one of our client (Michel). The next experiment was to first straighten these images to make them look like photographs taken from above, and then train the network with straightened images.
Let’s look at the different subtasks our data scientist had to perform:
- Code the pre-processing of the images;
- Launch an algorithm training using the pre-processed images;
- Wait for the algorithm to train;
- Retrieve the results of the training;
- Compute the performances of the algorithm trained on straightened images.
We decided to split these experiments in two phases: starting a new training (steps 1-2) and getting the results (4-5). In our example, the experiment was “Train MaskRCNN on straightened images”. Split in two tasks, it became:

We therefore had two subtasks for each experiment, which now didn’t include any waiting. This allowed the data scientists to estimate each subtask separately, know precisely the time spent on each and react in case one task took longer than expected.
During the following six weeks, the team identified 15 different occurrences of tasks that exceeded the planned schedule, over 24 different experiments. For more than half the experiments, one of the subtasks exceeded the estimation of the team! Using a red bin approach, the team analyzed each subtask to address the root causes of the problem.
Let me share an example of how we used the 5 whys (well, 4 whys in this instance) on an experiment to add new images to our training dataset. The problem we faced was that a data scientist took 1.5 hours more than expected to generate the new performance metrics.
- Why? The performance analysis script caused an error.
- Why? The computer ran out of memory during the execution of the script.
At this point, the first action of the data scientist was simply to expand the computer’s memory. Further investigation on the red-binned task led to new discoveries:
- Why did the computer run out of memory? The neural network was reloaded for each image on which it was tested.
- Why? A single piece of code was both loading the neural network and making the calculations, violating a standard coding rule: “Each function performs only one task.”
Here is the corresponding code (slightly edited for simplicity):
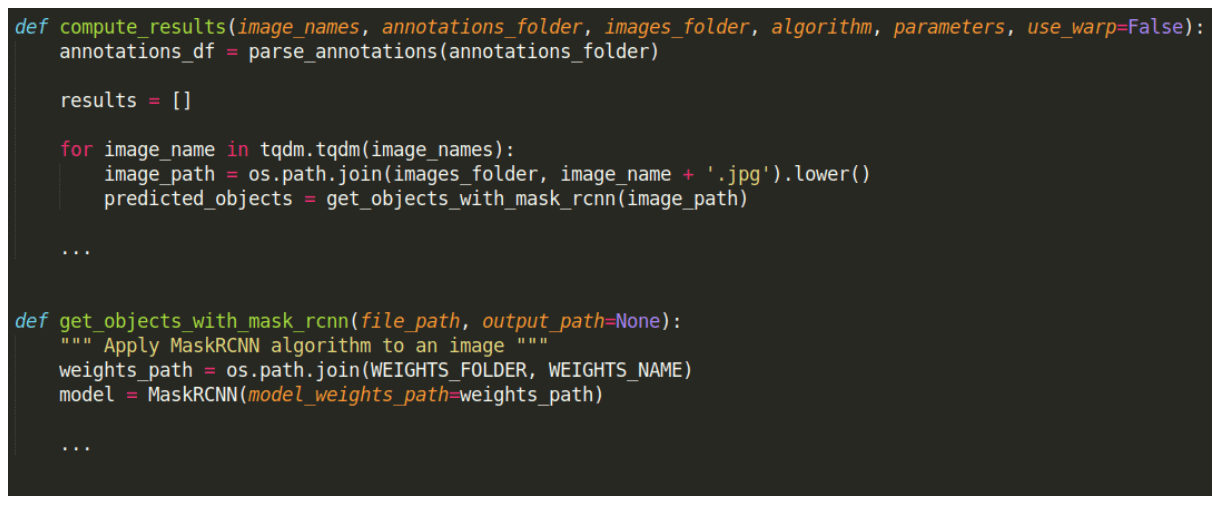
The last line shows the neural network model being reloaded in memory inside a function that is supposed to only retrieve the results, which is unexpected, and as a side effect increases memory usage.
This investigation led to improvements in the organization of that part of the code:
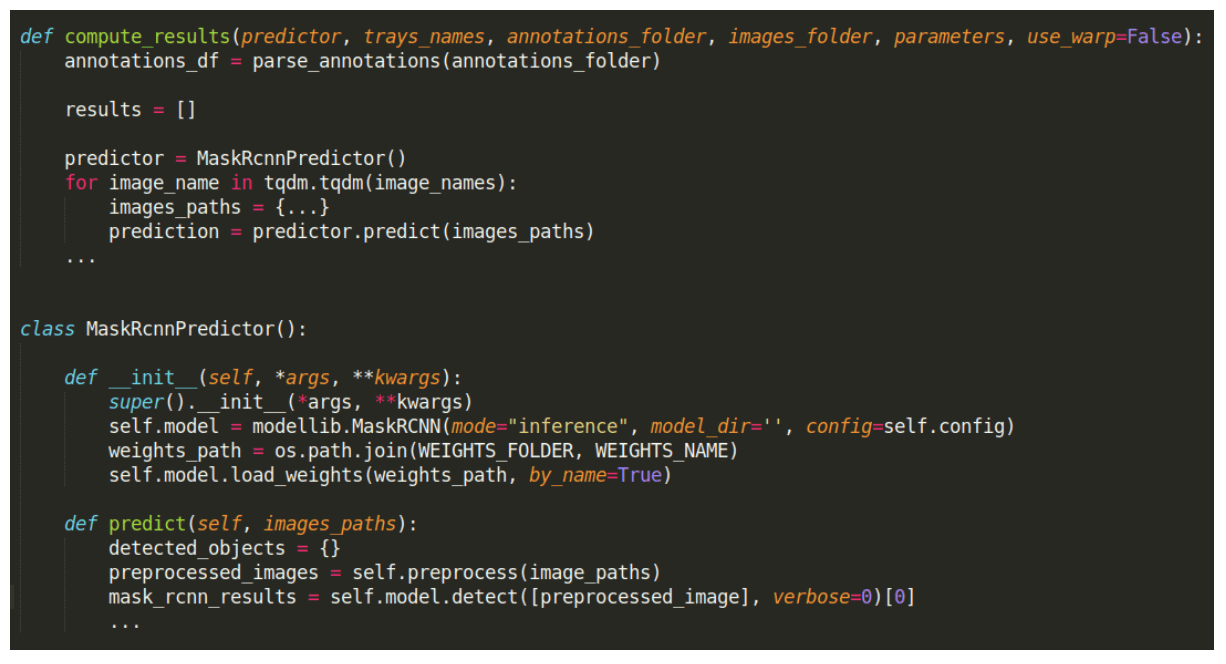
Now the model loading happens in the initialization function (__init__), and the predict function only handles getting the results.
Looking at the red-binned tasks also led to a couple of unexpected findings. Contrary to what I thought, most of the problems occured in the last stage of the experiment (determining whether the performance metrics of the algorithms had improved). Only three out of 15 exceeded tasks concerned writing and launching the training algorithms.
Some common causes have already started to appear:
- Three out of the 15 red-binned tasks were linked to a training or metrics calculation that had to be restarted after the servers ran out of memory. This led to an experiment in our newcomers’ training: we added a step for being able to estimate the necessary RAM required for training a given algorithm.
- Two tasks had ended up in the red bin because of wrong conversions from centimeters to pixels when calculating the distance between objects. The team addressed this recurring issue by creating a Distance class in the code that held both values.
Splitting each experiment into smaller tasks in order to remove work-in-progress helped us to highlight the actual problems the team was having. As the observations above show, analyzing small problems through red bins can show a great - and humbling - way to match my preconceptions with the reality of our work.
THE AUTHOR

Read more


FEATURE – Pure and simple management by indicators can be a trap leading us to make decisions that are inconsistent with the real needs of a company. The balance between facts and data is key.

INTERVIEW – Lean is making inroads in the Middle East! In this interview, a Senior VP of Gerab National Enterprises tells us how the company is using lean to reinvent itself as a project management firm.

FEATURE – What is the role of middle managers in a transformation and how can we ensure they can fulfil that role – instead of being blamed for the failure of the initiative and even excluded from it?

BUILDING BRIDGES – In this article, we learn how a team of software developers leverages the lean concept of “red bins” to ensure the quality of the code they write.